在人工智能领域模型竞争日趋白热化之际,国内DeepSeek和小米模型展开激进的降价策略,国际上Anthropic与Google持续推陈出新,在此背景下,埃隆·马斯克也迅速入局。
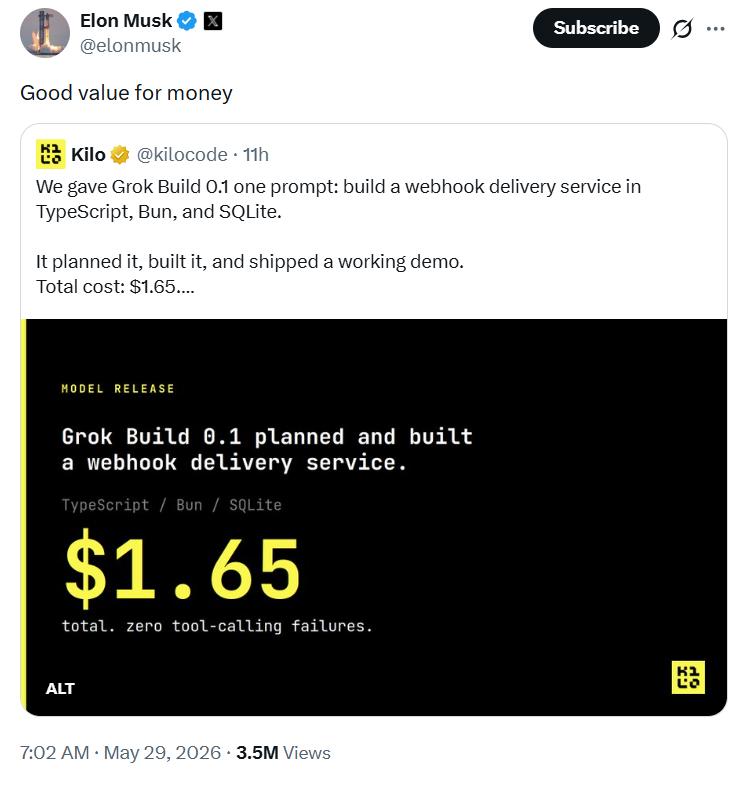
近期,马斯克在xAI平台高调转发了一条消息,意图撼动AI开发者社区。由Kilo Code智能体平台进行的一项测试结果显示,针对一个模糊而开放的指令,xAI最新编程模型Grok Build 0.1在极短时间内,便能规划、编写并成功上线一个包含复杂退避重试机制、安全签名验证及数据库持久化功能的Webhook后端微服务。
更引人注目的是,完成整个流程的总成本仅为1.65美元。马斯克对此亲自点赞并评价道:“物超所值”(Good value for money)。在全球GPT-5.5及Claude Opus 4.8等模型定价高昂的当下,Grok Build 0.1的这一举动,被视为其试图复制中国大模型路线,以极致性价比重新定义AI编程。
然而,业内对马斯克的此举看法不一。一些开发者认为,这可能是xAI在当前市场劣势下的一次精心策划的自救与豪赌。
细究Grok Build 0.1的市场定位,需要结合xAI旗下Grok系列模型当前的窘境。尽管此前Google发布的Gemini 3.5 Flash模型反响平平,但有观点认为“美国大豆包”的称号更适用于Grok。根据Artificial Analysis的最新数据,Grok系列模型在核心表现上已逐渐被“中美联军”所超越。除了OpenAI、Anthropic和Google这三大领先者外,阿里Qwen3.7 Max、月之暗面Kimi K2.6以及小米MiMo-V2.5-Pro等模型,在多项基准测试中已对Grok形成全面压制。尤其在编程和智能体领域,xAI的表现已跌出前十,在开发者社区中的关注度较低。
面对这种多重压力,马斯克采取了一项策略:效仿其合作伙伴兼OpenAI主要竞争对手Anthropic,专注于垂直编程领域。Grok Build 0.1正是这一战略的初步成果。其定价极具竞争力:输入每百万token 1美元,输出每百万token 2美元,远低于GPT-5.5和Opus 4.8的成本。
马斯克深谙开发者对价格和性能的敏感性,试图通过“试错自由”夺回市场份额。即使一次生成的代码未能成功运行,几美分的重试成本也易于接受。因此,马斯克希望通过这种“廉价劳动力”模式,从编程这一垂直领域突破OpenAI的市场垄断。
客观来看,Kilo Code的测试确实为马斯克和Grok赢得了声誉。它不仅展示了代码生成能力,更体现了惊人的Agentic工作流逻辑,甚至让资深后端工程师也感受到了职业危机。Kilo Code的技术报告指出,Grok Build 0.1有两大亮点:
首先是架构师级别的规划深度。该模型在接到指令后,不会盲目开始编写代码,而是像经验丰富的架构师一样,首先进行联网搜索,研究行业标准,并向测试者提出关键的架构问题。这一“规划阶段”仅花费0.17美元,但却产出了一份详细的架构图、Drizzle Schema定义和风险评估报告。这种“先思考再行动”的模式,有效避免了早期AI编程常见的“答非所问”问题。
其次是卓越的自主纠错能力。在编码阶段,Grok能以每秒120 token的速度流畅输出代码。即使在配置环境时遇到兼容性问题或类型错误,Grok也能在没有人工干预的情况下,自主诊断错误、调整导入路径、修改配置文件,最终完成了26个工程文件的搭建。Kilo Code特别强调,整个过程零工具调用失败,总成本仅1.48美元,这种流畅的Agentic体验充分体现了“Build”这一名字的含义。
然而,当人们为这一“物超所值”的生产力欢呼时,社交平台和技术社区也出现了冷静的声音。马斯克试图重新定义AI编程性价比,但Grok Build 0.1的低价是基于与昂贵的GPT-5.5和Opus 4.8进行对比。如果放眼全球,尤其是在国产大模型已将价格打到“地板价”的市场中,其价格优势便不那么明显。有评论指出,免费的DeepSeek Flash也能处理同等规模的问题。
技术社区Linux.do对该模型的评价也并不高,认为其“干活不主动、理解能力差”。这揭示了一个现实:马斯克认为的“白菜价”在国产大模型的低价竞争面前,不具备绝对的代差优势。此外,目前AI竞争的关键在于性能领先或极致性价比,处于中间地带的模型实际应用价值有限。
Grok Build 0.1的一个致命短板是其仅256K的上下文窗口。在长上下文模型层出不穷、1M窗口已成为复杂任务标配的当下,256K显得捉襟见肘。这意味着Grok在“从零构建项目”时表现出色,但一旦进入真实的大型代码库项目,它将无法加载足够的历史上下文,导致幻觉频出、指令遵循能力差和主动性不足。
马斯克此次发布模型依然采用“拒绝跑分、纯靠晒单”的营销策略。然而,一年前的编程模型Grok Code Fast 1也曾因缺乏第三方评测而饱受诟病。尽管对第三方评测机构和基准测试结果的信任度有所下降,但缺乏第三方测试支持的发布,难免被质疑存在过度包装和幸存者偏差。
深入分析Grok Build 0.1生成代码的源代码,结果却不仅是生产力的飞跃,还伴随着安全漏洞的博弈。尽管Grok生成的代码工程结构规范,并配置了SQLite的WAL模式和非破坏性重试机制,但专业的代码审查发现了一些关键的bug:
首先,在Webhook最关键的签名比对环节,Grok默认使用了普通的字符串检查,而非抗时序攻击的crypto.timingSafeEqual,这为潜在的黑客攻击留下了漏洞。
其次,Grok在查询接口时无意中泄露了本应加密保存的密钥字段(encryptedSecret),尽管已加密,但这完全违背了它在README中制定的安全规范。
最后,Grok虽然编写了14个基础单元测试,但在自动暂停机制、重试循环的集成测试等复杂业务逻辑上未能提供有效的解决方案,有避重就轻之嫌。
这为全球AI开发者和企业敲响了警钟:AI不会取代程序员,但会促使程序员成为更严格的“技术审查员”。如果开发者盲目相信仅凭文字描述便能构建复杂架构,那么Grok节省下的成本,最终可能转化为成千上万倍的安全补丁和系统重构的代价。
此外,零门槛编程不等于人人都能成为程序员,也不等于能够开发出可运行的应用并实现商业价值。对于不具备编程背景的人来说,Grok的上述漏洞可能难以理解,更遑论修复和完善。而这些bug,恰恰是实现商业价值过程中必须避免的。
总的来说,Grok Build 0.1的发布及Kilo Code的测试,对xAI而言无疑是一次成功的宣传。它精准击中了开发者对“廉价、好用、懂工程架构、能自主Debug”的期望,并证明了马斯克在垂直编程领域具备一定的竞争力。对于需要快速原型开发和逻辑验证的国外开发者而言,它是一款趁手的工具。
然而,要使其真正成为“美国编程版DeepSeek”,或重塑全球编程模型格局,xAI仍有很长的路要走。在全球AI竞争进入深水区的下半场,单纯的价格战难以持久维系竞争优势。能否处理超长上下文、在复杂遗留代码中精准重构、以及在生成代码的同时严守安全底线,才是xAI能否逆袭领先者的关键。马斯克的这一布局已经展开,但其最终成效尚待市场检验。即便当前能以低廉成本解决需求,用户仍需仔细审查每一行代码,以防潜在的安全风险。