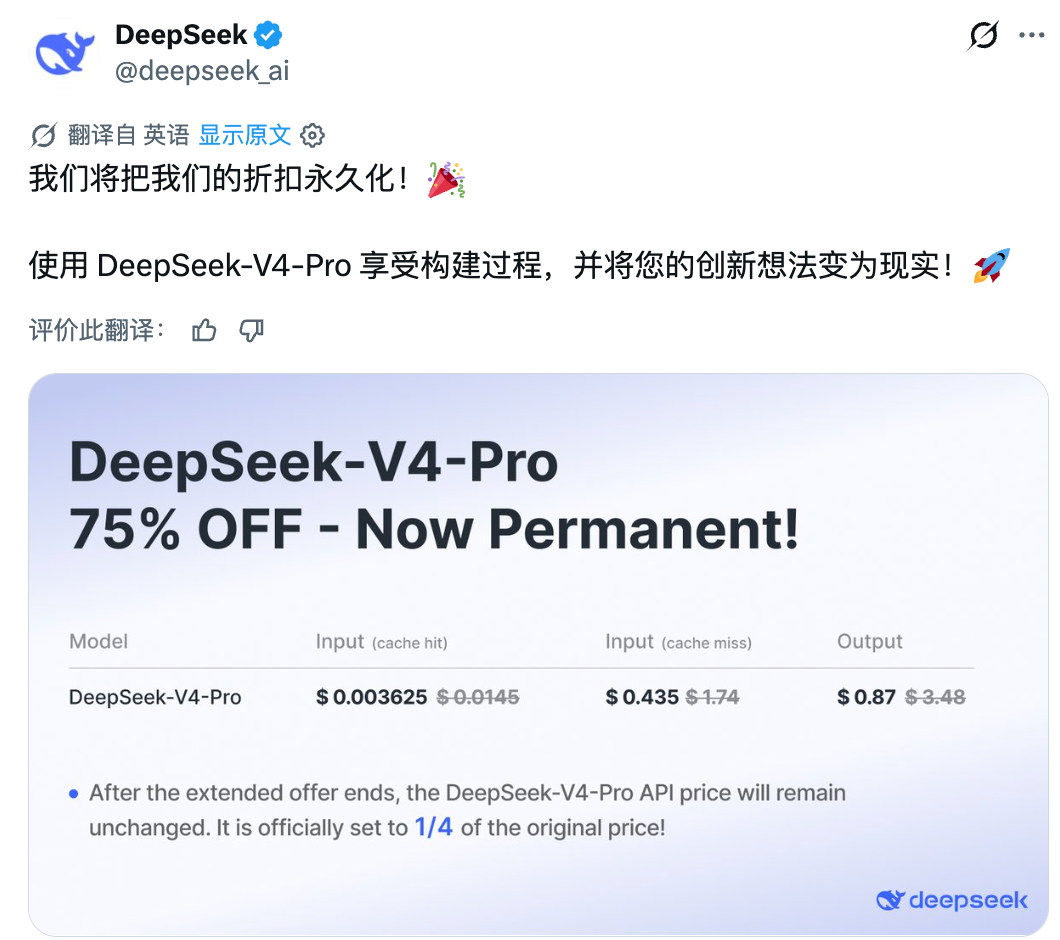
DeepSeek公司日前宣布,其V4-Pro API的折扣方案将永久生效,在全球范围内同步大幅调整价格。调整后,基础输入价格从每百万Token 1.74美元降至0.435美元,输出价格则由3.48美元降至0.87美元。此外,针对全API产品线的输入缓存命中,DeepSeek提供了更为优惠的定价,仅为每百万Token 0.003625美元,其定价策略被形象地描述为“拼多多式”的极致成本优势。
这一大胆的定价策略迅速在社交媒体上引发热烈反响,许多用户称赞DeepSeek创始人梁文锋为“AI圈的赛博菩萨”、“锋神”。尽管DeepSeek此前一直以其亲民的定价策略闻名于世,但此次降价的意义非同寻常,因为它发生在当前全球AI服务普遍涨价的背景下。
有报道称,在DeepSeek正在进行的一轮创纪录的A轮融资中,梁文锋个人计划出资高达200亿元人民币,占融资总额的40%。在大多数公司急于通过融资美化财务状况以吸引投资者时,梁文锋似乎选择了一条不同的道路。他并未以商业盈利前景作为主要卖点,而是坚定地践行开源理念并追求通用人工智能(AGI)的愿景。此次降价行动,恰恰印证了其言出必行的决心。这种做法曾让人联想到拼多多,其联合创始人也曾在财报电话会议中坦言未来利润可能面临下降,引发股价波动。
与一些公司口头倡导AI民主化,实际却愈发封闭的趋势形成对比,梁文锋正通过实际行动推动AI技术的普及和普惠。然而,这并非意味着梁文锋是一位纯粹的“活菩萨”。作为一名企业家,他所选择的开源普惠模式,代表的是一种独特的商业战略,在当前市场环境下显得尤为稀缺。
当前,AI服务的成本持续攀升。微软近期取消了内部使用的Claude Code许可证,原因在于基于Token的计费方式成本过高,即便是拥有强大云计算资源的微软也难以承受。无独有偶,Uber首席技术官在今年4月报告称,公司为2026年全年设定的AI预算在短短四个月内便已耗尽,其中95%的工程师每月都在使用AI编程工具,70%的代码提交由AI生成。他坦言,预算已被彻底突破,需要重新规划。
大型企业在AI Token上的预算消耗速度远超预期,这固然有员工使用习惯的因素,但AI服务本身成本的不断上涨才是根本原因。过去一年中,美国AI软件价格上涨了20%至37%。Anthropic、OpenAI和Google等主要AI服务提供商在过去六个月内也悄然提高了实际价格。
此前流行的观点认为,AI应用规模越大,工业化程度越高,成本就会越低,从而使企业受益。然而,现实情况并非如此乐观。AI的定价正逐步由供需关系主导,而非成本决定。大约在过去两年,AI市场的供需关系发生了根本性逆转。过去,各大厂商积极推广AI以教育市场,AI服务通常伴随着补贴。如今,随着AI编程、AI文档、AIGC甚至AI搜索的普及,用户对AI的需求日益增长,AI补贴时代已然终结。
随着使用人数的增加和需求的爆发,Token资源日益紧张,导致算力短缺从GPU蔓延至CPU、存储甚至网络带宽。英特尔、美光、SK海力士、三星电子、闪迪以及国内的江波龙等半导体巨头都因此受益。这些半导体公司在近年取得的营收增长,并非仅来源于OpenAI、甲骨文、微软等公司的投资,而是源于整个AI生态的旺盛需求。同时,ChatGPT、Claude、Gemini、豆包等AI产品通过免费与付费的“等级森严”服务模式,也让个人用户在选择上陷入纠结。
这类似于网约车市场的发展轨迹:在市场推广初期,用户可以享受免费或补贴乘坐专车的待遇,由资本承担费用。一旦用户习惯养成,补贴便会终止,价格回归正常水平,届时需要乘坐地铁的仍然需要乘坐地铁。AI市场亦是如此。因此,在全球AI Token普遍涨价的大背景下,DeepSeek逆势降价的举动,不仅仅体现了其“赛博菩萨”式的个人魄力,更展现了其反向定价权:即便是如此低廉的价格,DeepSeek仍能保持正常运行,并且服务质量不打折扣。
实际上,DeepSeek完全可以选择不以如此低廉的价格运营。这引发了人们的担忧:DeepSeek会否成为AI时代的Linux?Linux对IT产业的贡献巨大,超越了Windows和安卓(安卓内核基于Linux),但由于其开源性质,并未催生出像微软或Google这样的商业巨头。DeepSeek目前影响力显著,但在商业能力上仍落后于硅谷三大巨头,甚至与国内的Kimi、MiniMax、智谱三家相比也存在差距。在2025年,排名前四的AI公司的营收预计为:智谱(7.24亿元)> MiniMax(约5.6亿元)>月之暗面(约2亿元)> DeepSeek(未知但更低)。
梁文锋通过AI量化交易积累了财富,得以个人出资200亿元投资DeepSeek。然而,仅凭“用爱发电”的模式难以长期维系。此外,在开源模式下,其他公司可以对DeepSeek的技术进行蒸馏、部署和二次训练,这无疑会削弱其技术护城河。因此,我们经常会看到“刷榜”新闻,例如智谱的GLM-5.1开源后在SWE-bench Pro基准测试中刷新全球纪录,小米的MiMo-V2.5-Pro登顶全球开源大模型榜首等。麻省理工学院与Hugging Face的联合报告显示,过去一年中国研发的开源模型在全球下载量占比高达17.1%,首次超越美国的15.8%,位居全球第一。
这就不难理解为何硅谷越来越多的人呼吁必须出现美国版的DeepSeek,以避免AI产业重演Shein、Temu或TikTok的故事。“如果美国没有崛起的开源冠军,世界将由任何一个能够生产最强大、最稳定、最便宜、可定制、可扩展、适应个人和商业需求的开源模型和开源软件的国家掌控。”这涉及大国竞争的宏大叙事,其背后的竞争是实实在在的。
DeepSeek的崛起本身就带有自主替代的叙事。V4模型支持昇腾算力令人鼓舞,国产算力驱动下,DeepSeek当前展现的价格竞争力可能只是冰山一角。在其技术报告中,DeepSeek暗示随着下半年昇腾950超节点批量上市,V4-Pro的价格还将大幅下调,预示着未来会有更优惠的价格。
中国在高级AI人才方面也拥有优势。尽管AI人才普遍身价昂贵,但中国的人才成本相对较低。雷军以千万年薪从DeepSeek挖走罗福莉曾引发关注,而同期扎克伯格却可能需要花费10亿美元来挖角,甚至进行“收购式招聘”。然而,花费10亿美元聘请的人才与千万年薪的人才所创造的成果,其差距显然远未达到700倍之巨,这种AI人才的价差最终会转化为Token生产体系的系统性价格优势。
更深层次的竞争力体现在能源体系上,这正是英伟达CEO黄仁勋所提出的AI“五层蛋糕”中的第一层。
AI的最终发展受限于算力,而算力的最终形态则依赖于电力。2026年4月,DeepSeek在内蒙古乌兰察布招聘高级数据中心运维工程师和高级交付经理,这表明他们正在西部建设“Token工厂”,旨在将成本优势从软件层面延伸至物理层面。早前,快手在乌兰察布建设数据中心的原因也是因为这里靠近电厂,且气候适宜于散热。值得一提的是,中国西部地区的绿色电力价格约为每度0.2-0.3元,仅为欧美地区的1/5到1/4。
不仅是西部绿电具备竞争力。国际能源署2025年的数据显示,中国发电总装机容量已超过2300GW,占全球约22%,位居世界第一;美国约为1300GW。更重要的是,中国拥有全球最完整的电力结构,涵盖了火电、水电、风电、核电和光伏等所有类型。数据显示,中国工业电价长期维持在每千瓦时0.06到0.08美元,而美国加州的工业电价已接近0.18美元,德国部分地区甚至超过0.25美元,这意味着训练一个万卡集群,中国天然比欧美便宜数十个百分点。
在AI大模型的运营成本中,电力成本高达总运营成本的60%-70%。这不仅包括模型运行所需的电力,还包括散热这一巨大开销。中国的基础设施建设能力也体现在这方面,例如将数据中心直接建在海底,既能利用海上风电就近供电,又能利用海水循环进行免费散热。此外,“西电东送”和“东数西算”等宏大项目,极大地增强了电力和算力的区域调度能力,贵州、内蒙古、宁夏等地早已成为“东数西算”的核心节点,为AI算力中心向西部迁移做好了充分准备。
因此,使用中国的AI,本质上就是使用在更具竞争力的能源体系下训练出的AI——更经济、更普惠的AI。这也是春节后Kimi、MiniMax等国产AI产品海外营收激增的原因之一,不仅仅是因为算法更强,更是因为它们“开了电价外挂”。
英伟达能够定义高端算力的价格,但DeepSeek等公司却在掌握Token的定价权。你可能会质疑AI是否“便宜无好货”。确实,AI服务通常是“一分钱一分货”,DeepSeek V4只是将开源与闭源模型之间的差距缩小到了历史最低水平。官方也坦言其与GPT等顶尖模型在客观上存在差距,并且目前仍不支持多模态生成,只能识别图片而不能生成。
但这并未阻止社区用户涌向DeepSeek。原因在于,大多数真实的商业场景并不需要每次都调用世界上最强的模型。例如咨询、客服、摘要、翻译、代码补全、企业知识库和自动化流程等任务,所需要的是“勉强能用+足够便宜+足够稳定”的服务,而非最高的智能水平。当DeepSeek V4的推理成本仅为GPT-5.5的约1%(Flash版)到11%(Pro版)时,企业可以通过相同的预算调用数十倍的Token,尝试更多的提示链条,迭代更多的Agent工作流,最终反而有可能取得更好的效果。毕竟AI本身就是一个“概率”游戏,只要足够便宜,能够达到预期结果,何乐而不为?
因此,AI服务越昂贵,DeepSeek的低价策略就越有价值,DeepSeek这家公司也将随之变得更有价值。梁文锋及其投资者对此心知肚明。