谷歌推出 Gemini 3.5 Flash 模型已逾一周,公司首席执行官皮查伊曾高调宣称其性能超越 3.1 Pro,并视其为 Agent 时代的核心驱动力。然而,用户反馈却出乎意料,除了速度方面的优势外,该模型普遍被批评输出内容常有偏差、信息冗余,并且在实际运作中 Token 消耗量巨大。
针对这些问题,谷歌 Antigravity 负责人瓦伦·莫汉于 5 月 25 日表示,已引入 Gemini 3.5 Flash (Low) 模型以优化资源利用。他指出,内部测试数据显示,在处理简易任务时,此模型相较于 Gemini 3.5 Flash (Medium) 可减少约 45% 的 Token 生成量,并在软件工程(SWE)任务中的表现普遍优于其前代旗舰模型 Gemini 3 Flash (High)。
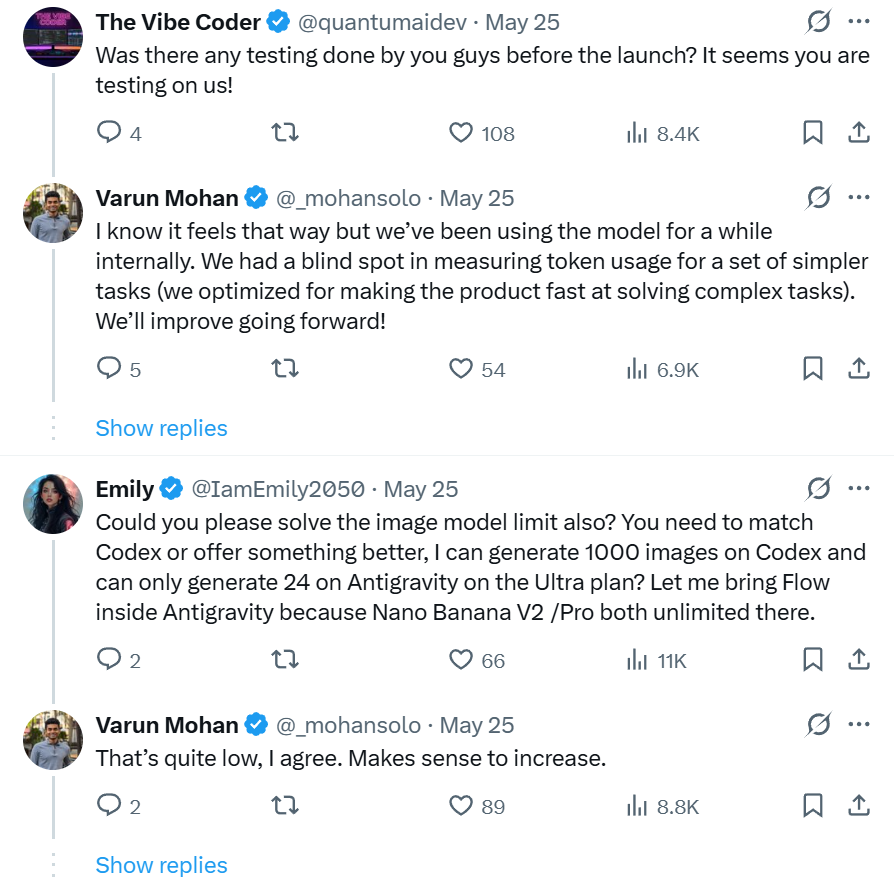
然而,瓦伦的这一声明并未能赢得用户认可。他的社交媒体评论区随即被大量质疑声所淹没。有评论直接质问:“你们的产品进行过测试吗?看起来我们才是测试者!” 另一条热门评论则提及图片生成能力限制,对比谷歌产品与其竞争对手的表现存在差距。
Gemini 3.0 Pro 问世时曾赢得业界广泛赞誉,甚至促使竞争对手 OpenAI 警觉。然而,Gemini 3.5 Flash 的表现却令谷歌陷入尴尬境地,似乎即将重蹈 Meta 的覆辙。这引发了人们对于谷歌模型策略的疑问。
目前来看,Gemini 3.5 Flash 的表现远未达到预期。用户普遍反映其速度虽快,但质量欠佳。尽管皮查伊在发布会上强调了模型的经济性,但实际情况却大相径庭。
依据官方定价,Gemini 3.5 Flash 每百万输入 Token 收费 1.5 美元,每百万输出 Token 收费 9 美元,这确实低于 Claude Opus 4.7 的 5 美元输入和 25 美元输出费用。然而,决定实际成本的关键在于完成任务所需的 Token 总量。
Artificial Analysis 的一项全面评估测试显示,Gemini 3.5 Flash 完成所有任务的总成本高达 1552 美元,而 Gemini 3 Flash 仅需 282 美元,前者是后者的 5.5 倍。即使与 Gemini 3.1 Pro 相比,Flash 的成本也高出 75%,达到约 870 美元。更令人困惑的是,Gemini 3.5 Flash 的任务完成费用甚至超过了 GPT-5.5 medium。
高成本的症结主要在于完成任务所需的对话轮次。在 Agent 评估中,Flash 模型平均每个任务需要 49 轮对话。每次对话都会将完整的历史记录输入模型,从而导致 Token 成本急剧攀升。相比之下,GPT-5.5 或 Opus 4.7 完成相同任务通常只需大约 20 轮。
因此,谷歌宣称的“成本不到一半”仅指单位 Token 价格,但对用户而言,Gemini 3.5 Flash 并不经济。此外,Gemini 3.5 Flash 的输出内容也过于冗长。
例如,如果向 Gemini 3.1 Pro 咨询一道技术问题,模型会直接提供代码和简洁的解释。而同样的请求发送给 3.5 Flash,模型会先阐述背景,然后列出三种可能的解决方案并逐一分析优缺点,最后才给出代码。尽管内容看似全面,但大部分信息都是无关紧要的,且这些冗余信息都会计入 Token 消耗并产生费用。
在复杂任务中,Token 消耗量更是惊人。有用户反映,让 Flash 执行多步骤代码重构任务时,模型频繁在不同文件间切换,每次切换都需重新加载上下文,最终 Token 消耗是预期的三倍以上。另有用户表示,仅仅是输入一个复杂的提示词,就触发了 5 小时使用限制。
谷歌自 I/O 2026 后悄然调整了 AI Pro 订阅的额度规则,从固定消息数改为基于计算资源的配额。这意味着,即使模型回复的内容不变,如果任务需要模型进行更多“思考”,用户支付的费用也会更高。然而,用户难以预估任务将消耗多少算力,更无法准确推算剩余配额。有用户发现,一个简单的问候语就可能消耗大量 Token,而一个长时间运行的任务反而消耗较少。
有用户在境外论坛上直言,新规定如同“骗局”,单个提示词就消耗了 13% 的配额,某些 Gemini AI Plus 功能一次性甚至可能消耗近 30%。
Gemini 3.5 Flash 表现平平的原因,在其基准测试结果中有所体现。其表现非常不均衡。
Gemini 3.5 Flash 在 Terminal-Bench 2.1、MCP Atlas、Toolathlon、OSWorld 等 Agent, 工具调用和代码执行榜单上表现不俗,分别取得了 76.2% 和 83.6% 的头部成绩。这些测试主要衡量模型调用工具、执行命令和完成多步骤操作的能力,Flash 在这方面的优势确实显著。
然而,在更能体现“智能”水平的综合推理榜单上,其表现则不尽如人意。在 Humanity’s Last Exam 中,其得分仅为 40.2%,低于 Gemini 3.1 Pro 的 44.4% 和 Claude Opus 4.7 的 46.9%。在 ARC-AGI-2 中,其得分 72.1% 也低于 Gemini 3.1 Pro 的 77.1% 和 GPT-5.5 的 84.6%。GDPval-AA 的得分同样低于 Claude Opus 和 GPT-5.5。这表明 Gemini 3.5 Flash 在复杂推理、长链分析和创意判断等方面的“智力”水平仍有待提升。
记忆能力方面也存在问题。谷歌宣传 Gemini 3.5 Flash 拥有高达 1M Token 的上下文,但在模型卡片的 MRCR v2 长上下文测试中,128k 平均成绩为 77.3%,而 1M 的点对点测试结果仅为 26.6%。这意味着 Gemini 3.5 Flash 虽能处理大量信息,但在实际应用中可能容易混淆。
Artificial Analysis 的独立测试直接反驳了谷歌的说法。在编程指数(Coding Index)上,分析机构为 Flash 打出了 45.0 分,低于 Gemini 3.1 Pro 的 56.5 分,更远低于 GPT-5.5。
谷歌在 I/O 2026 大会上宣布,Gemini 将成为其所有产品的连接层。这意味着 Gemini 3.5 Flash 已深度整合进谷歌的绝大部分产品中,致使外界认为“Gemini 正变得无处不在”。
过去,用户若对某个 AI 产品不满,可以轻易替换或选择不使用。然而,当谷歌将 Gemini 植入所有入口后,Gemini 3.5 Flash 的糟糕体验便开始影响谷歌所有产品的整体用户感受。
最典型的案例便是 AI Overview 和 AI Mode 中的“disregard/ignore/stop”故障。当用户搜索这些词语时,谷歌 AI Overview 会误将其判断为指令,从而导致搜索结果异常或空白。例如,有用户在 X 平台上发帖称,搜索“disregard”一词时,AI Overview 并未提供定义,而是回复“明白了!我会忽略之前的提示,重新开始。”同样,搜索“stop”和“ignore”时,AI Overview 也分别回复“没问题。我已经停止当前操作。”和“收到。消息已忽略。”
据分析,这批词语被 Gemini 3.5 Flash 识别为对话指令,引发了上述问题。不止这几个词,经网友测试,“remember”、“start”、“finished”、“forget”等词汇也会触发类似故障。即便在搜索词中加入“definition”,也无法使 AI Overview 恢复正常。
谷歌针对此问题回应称,此故障与 I/O 新搜索发布无关,系 AI Overviews 自身问题,团队正在积极修复。搜索作为谷歌的核心业务,一旦出现问题,公众便会质疑“谷歌是否面临困境”。
因此,当前的焦点已转向 Gemini 3.5 Pro。外界真正关注的并非谷歌能否将 AI 融入其所有产品(这一点谷歌已实现),而是谷歌能否推出一款足够智能、稳定且具有说服力的旗舰模型,以重新证明其在模型能力方面并未落后。显然,Gemini 3.5 Flash 无法胜任此重任。它作为执行型模型,虽速度快、能干活,但智力有限,更适合担任 Agent 架构中的子任务执行器,配合强大的规划器使用,而非作为谷歌在 AI 时代的门面担当。
这使得人们将期望寄托于 Gemini 3.5 Pro。目前,Gemini 3.5 Pro 尚处于内部测试阶段。官方博客透露:“我们也在全力开发 3.5 Pro。它已在内部投入使用,预计下个月(6 月)发布。”
谷歌产品负责人图尔西·多希解释道:“3.5 Pro 类似于项目经理,负责规划任务执行路径;Flash 则像执行团队,专注于完成具体任务。需要推理和规划的复杂场景应由更大的 Pro 模型处理,而快速调用工具、批量处理任务的场景则 Flash 足矣。” 这一架构设计本身并无问题,症结在于 Pro 模型尚未推出,许多场景只能由 Flash 独自应对。
因此,Gemini 3.5 Pro 的发布将成为一次重要的验证。若 3.5 Pro 表现良好,谷歌仍有机会挽回声誉,其可能会解释称“全线嵌入 Flash 仅为一次尝试,用户体验不佳之处我们深表歉意,但 3.5 Pro 绝对好用,欢迎体验。” 届时,Flash 的问题或可被视为一种权宜之计,而 Pro 才是谷歌实力的真正体现。
然而,如果 3.5 Pro 的表现也令人失望,那么谷歌在 AI 领域的布局恐将面临全面溃败的局面。届时,AI Overview 的低级错误、智能助手的冗长回复、WorkSpace 高昂的 Token 消耗以及 Antigravity 表现平平将共同拖累谷歌所有产品,使 Gemini 从优势转变为负担。
谷歌当前的处境颇为微妙。它拥有充足的资金、完善的基础设施以及 DeepMind 这样的强大支持,但自从 3.0 Pro 之后,它一直缺乏一款具有竞争力的旗舰模型。3.5 Pro 的任务正是弥补这一空白。若 3.5 Pro 未能成功,谷歌恐将步入 Meta 的后尘。
不过,谷歌并非全无亮点。在硬件领域,它展现出强劲的实力。
谷歌 2026 年第一季度的财报显示,公司收入达到了 1099 亿美元,同比增长 22%。其中,谷歌搜索及其他业务收入 604 亿美元,同比增长 19%;YouTube 广告收入约 99 亿美元,同比增长 11%;谷歌云收入 200 亿美元,同比增长 63%。这充分表明谷歌仍是一台高效的“赚钱机器”。
这份财报中最引人注目的数字是谷歌云 63% 的增长。皮查伊在财报电话会议上将云业务的增长归因于“强劲的需求”。这本质上揭示了谷歌的 TPU 硬件和数据中心销售业绩斐然。
基于谷歌模型构建的 AI 解决方案同比增长近 800%。Gemini Enterprise 的付费月活跃用户环比增长 40%。通过 API 使用的 AI Token 量增长至每分钟 160 亿个,较第四季度的 100 亿增长了 60%。
谷歌云的待履约合同金额在本季度翻番,达到 4620 亿美元。皮查伊表示:“显然,我们在短期内受算力限制。如果能满足需求,我们的云收入还会更高。我们正在克服这一阶段,并持续投资,同时具备强大的长期规划框架……我们看到了前所未有的机遇。” 公司预计将在未来 24 个月内完成 50% 的待履约合同。
尽管谷歌的基础模型表现不佳,编程工具 Antigravity 也不尽如人意,但其 TPU 业务却异常出色。这不禁让人怀疑,谷歌是否已忘记其作为互联网公司的本质,而正转向成为一家硬件公司。
Anthropic、Meta 等外部大客户正在租用或采购谷歌的 TPU 资源。Anthropic 在 5 月宣布与谷歌和博通签署了新的多年协议,扩大了对谷歌云 TPU 的使用。这笔交易使 Anthropic 获得了多达 100 万个谷歌 AI 计算芯片的使用权,价值数百亿美元,预计将在 2026 年提供超过 1 吉瓦的算力容量。
谷歌在 Google Cloud Next 2026 大会上发布了第八代 TPU,首次采用了双芯片设计,分别为训练和推理定制了专用架构:TPU 8t 和 TPU 8i。
其中,TPU 8t 专为大规模、计算密集型训练工作设计,具备更强的计算吞吐量和更宽的扩展带宽。TPU 8i 则专为低延迟推理工作负载设计,Agent 交互需要反复“思考、调用工具、再思考”,每一步的延迟累积到几十甚至上百步将严重影响效率,因此低延迟对于 Agent 至关重要。
可以这样理解:TPU 8t 主要用于模型训练。训练前沿大模型如同让数万块芯片同时进行马拉松比赛。关键不在于单块芯片的速度,而是数十万块芯片能否持续稳定运行。如果某个网络线损坏、某块芯片失灵或系统需要重启检查点,整个训练集群将因此浪费大量时间。
因此,谷歌表示 TPU 8t 的重点并非单纯强调“算力更强”,而是旨在减少训练过程中的中断。谷歌声称 TPU 8t 的设计目标是实现超过 97% 的有效吞吐量(goodput)。有效吞吐量可理解为实际用于工作的有效时间。例如,一台机器理论工作 100 小时,但因故障、等待和重启浪费了 10 小时,那么有效工作时间仅为 90 小时,有效吞吐量即为 90%。
谷歌表示,TPU 8t 的目标是超过 97% 的有效吞吐量,这意味着它希望大部分时间都真正用于训练,而不是等待修复、重启或网络恢复。为实现这一目标,谷歌为 TPU 8t 增加了多项横向提升性能的功能。例如,系统在发现故障时能自动绕行,无需手动停机修复。
TPU 8i 则专为 Agent 应用设计。Agent 推理过程复杂,并非一次性回答,而是涉及反复思考、查阅资料、调用工具、编写代码、再检查、再修正。一个任务可能调用模型数十甚至数百次。因此,TPU 8i 的重点是尽可能加快这些调用速度。
它配备 384MB 板载 SRAM,可视为芯片旁一块极速的小型存储区域。Agent 的短期记忆可在此处保留,从而在 Agent 需要使用这些记忆时直接获取,减少数据往返时间。它还采用了更多的 CPU 主机,即有更多“调度员”协助处理数据输入输出和任务协调。Agent 运行时不仅需要模型计算,还需要持续读取数据、发送请求、调用工具和获取结果,CPU 便是协助 TPU 处理这些杂项工作的。
微软曾预测,到 2028 年将有 13 亿个 Agent 投入运行,这正是谷歌将 TPU 分为 8t 和 8i 的原因,Agent 专用归 Agent,训练专用归训练。与谷歌传统的互联网业务相比,TPU 反而是他们目前最坚实的叙事。
然而,矛盾在于,Anthropic 可以利用 TPU 打造出 Claude Opus 4.7 和现在的 Mythos,而谷歌却只拿出了 Gemini 3.5 Flash。这恰如“橘生淮南则为橘,生于淮北则为枳”的写照。