在GTC 2026大会上,英伟达首席执行官黄仁勋发表了深刻见解,强调了AI时代计算的经济价值。他指出:“计算即收入,瓦特即收入,每一个Token都是收入!”这一论断,清晰地诠释了AI算力与经济效益的紧密联系。他进一步阐明,每瓦特能产出更多Token,则意味着更高的收益。
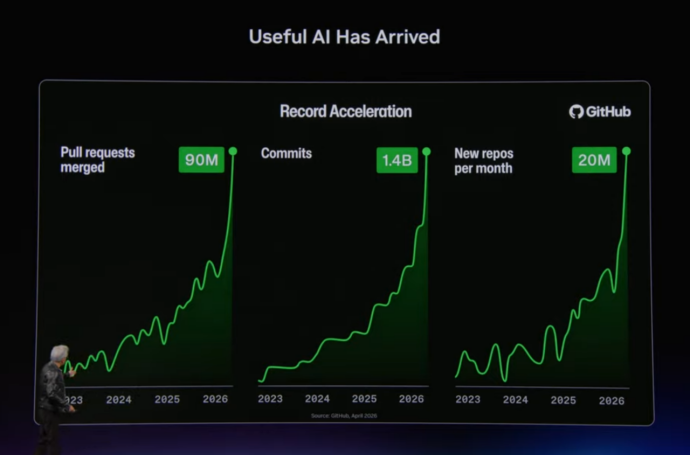
黄仁勋分享了一组令人瞩目的数据:在2026年前几个月,GitHub上的代码提交量实现了近三倍的增长。全球3000万软件开发者原本创造的3万亿美元薪酬价值,此刻正迸发出近9万亿美元的生产力。
本次GTC大会上,黄仁勋展示了一系列前沿创新产品。其中最受瞩目的是英伟达与微软共同设计的AI PC。此外,专为Agent时代构建的Vera Rubin及其完整生态系统、开源大模型Nemotron 3 Ultra,以及物理AI Cosmos 3及基于其衍生的Isaac人形机器人,都悉数亮相。这些创新共同构成了黄仁勋对未来十年计算模式的全面展望。
黄仁勋预言,微软与英伟达的深度合作将重新定义“AI PC”这一概念。
他在台上隆重展示了RTX Spark笔记本电脑。这款设备搭载了英伟达与联发科合作研发的N1X芯片,内置Blackwell RTX GPU,配备6144个CUDA核心和第五代Tensor Core,支持FP4精度。此外,它还集成了定制的20核Grace CPU,通过NVLink-C2C芯片互联技术连接,并拥有128GB统一内存。采用台积电3nm工艺制造,集成了700亿个晶体管。
RTX Spark能够运行数字生物学、地震处理、天体物理等领域的复杂应用,同时支持所有与CUDA相关的物理、生物学、基因组学、AI、计算机图形应用以及Windows应用程序。与传统笔记本电脑最显著的区别在于,RTX Spark可以在本地高效运行Agent。这些Agent能够理解口语指令、解析屏幕信息、读取文档,并协助用户完成任务。过去,此类AI功能通常依赖云端连接,而现在可以直接在笔记本电脑上实现。
黄仁勋表示,过去四十年,用户与电脑的交互方式是启动应用、点击图标、输入文字。然而,借助RTX Spark和Windows,用户只需提出需求,电脑即可自主完成工作。RTX Spark凝聚了英伟达三十年来的所有技术精髓,包括CUDA、RTX和AI平台,并将这些能力整合于单一芯片之中。本地Agent、前沿模型、创意工作流以及RTX游戏,现在都能在一台笔记本电脑上流畅运行。
这就是黄仁勋所描绘的“个人AI电脑”。
微软为RTX Spark进行了深度的平台优化。通过工作负载配置文件调度,Windows调度器能够更高效地在所有20个核心上扩展工作负载。无论是处理电子邮件还是在本地调试Agent代码,Windows调度器都能确保CPU提供最佳性能和效率。
此外,他们还启用了微软的电源与热管理框架,在保持设备散热的同时最大化性能和功耗。为了支持RTX Spark高达128GB的内存容量,微软提升了GPU可访问的系统内存上限,从而增加高内存系统上的GPU可用内存,使得加载更大的本地AI模型或渲染更复杂的项目成为可能。
微软还增强了Windows在统一内存系统上管理共享内存区域页面大小的方式,确保在重负载工作下仍能提供更大的内存页面,并赋予开发者优化CPU与GPU之间内存工作负载需求的灵活性。微软CEO萨提亚·纳德拉表示,他们的目标是通过Windows将无限智能带入每个家庭、每一张办公桌。
OpenClaw和Hermes Agent等开源Agent项目在GitHub和OpenRouter上的数据表现屡创新高,但由于无法在用户的主力电脑上安全、私密地运行,其普及速度一直受限。英伟达与微软的合作解决了这一难题。他们开发了新的Windows安全原语和英伟达OpenShell运行时,确保Agent在用户的完全掌控下安全运行。
新版Windows提供了身份验证、隔离、策略和端到端安全能力,可 natively 用于构建和运行Agent。英伟达OpenShell提供了一系列自定义功能,例如允许用户限制Agent的行为权限,根据用户隐私策略智能路由查询至本地模型,并在发送至云端模型的查询中隐藏个人信息。
Hermes Agent和OpenClaw在新Windows应用中采用了这套安全隐私层。这些应用使用户能够轻松安全地访问设备端Agent,这些Agent能够在Windows应用中执行任务、进行跨应用工作流推理、生成图像和视频、编写插件和应用代码,以及对本地文件进行语义搜索。
黄仁勋现场演示了在一台RTX Spark上运行的本地Agent如何协助他设计房屋。该Agent运行在Open Shell沙盒内,并与Hermes编排系统和云端Claude Sonnet相连接。它首先选择地点,并读取概念草图、风格情绪板、文字需求和设计意图。Agent利用笔记本上的工具,启动Rhino软件为场地建模,塑造地形、确定边界和建筑外壳,提出建筑形式,并针对成本、舒适性和质量进行优化。
形式确定后,Agent生成内部布局、墙体和流线,房屋结构由此成形。它能实时调整,自动放置门窗和结构元素,并自主发现和修正错误。获得批准后,Agent将模型从Rhino导出并导入Blender,材质和对象属性得以完整转移。接着,它调整材质、选择镜头,并由Blender渲染房屋。Agent利用Flux模型生成多个视角和光照条件。整个设计过程完全由Agent自主完成。
这就是黄仁勋所说的“新PC”。过去,用户操作电脑需要打开软件、点击鼠标、敲击键盘。现在,用户可以直接告诉Agent需要完成的任务,Agent便能自主操作各种软件来完成。
RTX Spark不仅为Agent设计,它本身也是一台功能完备的创作与游戏电脑。用户可以通过OptiX和DLSS渲染超大的90GB 3D场景,利用Blackwell解码器编辑12K 4:2:2视频,运行1200亿参数、100万Token上下文的大语言模型,并以1440p分辨率、超过100帧的流畅度畅玩支持光线追踪、DLSS和Reflex的AAA游戏。
RTX Spark还将支持新的RTX功能,包括DLSS 4.5光线重建,该技术采用第二代Transformer模型,将应用于Blender 5.3和数十款游戏中。此外,RTX Video还将支持4倍帧生成,该功能将整合到ComfyUI中。RTX Spark是一款笔记本电脑,但黄仁勋同时宣布推出桌面和工作站版本的DGX Spark。
DGX Spark拥有768GB内存,能够运行万亿参数级的大模型,提供20 petaflops的算力,每秒8TB内存带宽,可放置于办公桌上。对于大语言模型开发者或Agent开发者而言,这使得本地训练和测试模型成为可能,待部署时再将模型迁移至云端。黄仁勋表示,回想15至20年前的电话,如今智能手机的核心功能早已超越通话。PC也将经历类似的变革。十年后的PC将不再仅仅是启动软件、点击鼠标的工具。
华硕、戴尔、惠普、联想、微软Surface和微星将于今年秋季推出搭载RTX Spark的超薄Windows笔记本电脑和紧凑型台式机,这些设备将提供全天候电池续航和优质显示屏。宏碁和技嘉的型号将随后上市。黄仁勋并未透露具体价格。
黄仁勋随后宣布,Vera Rubin平台已全面投入生产。Vera Rubin是一套五机架规模的AI超级计算机系统,专为运行Agent设计。
该系统包含五种主要机架:Vera Rubin NVL72负责提示理解、上下文处理、推理和规划,是Agent的“大脑”;Vera CPU机架,单个液冷机架内安装256颗Vera CPU,负责协调模型、管理内存、调用工具;Groq 3 LPX机架,配备256个Groq 3 LPU横跨16个托架,提供每秒40PB的SRAM带宽,实现超低延迟的Token生成,其中NVL72负责高吞吐,Groq LPU负责低延迟;Vera BlueField-4 STX存储机架,作为Agent的记忆存储区,负责存储处理、加速和片上安全;以及NVIDIA Spectrum-X Ethernet CPO网络机架,该机架配备共封装光学技术的以太网交换机,拥有200Gb/s SerDes,并与台积电合作进行芯片级封装和超高功率磷化铟激光模块。
Vera Rubin平台由七颗全新芯片构成。它们采用台积电3nm制程和CoWoS-L封装技术,HBM内存由美光、SK海力士和三星提供。一块Vera Rubin计算板上集成了万亿级晶体管和超过18000个元件。整个机架包含18个计算托盘、9个热插拔NVLink交换托盘、高效液冷歧管和汇流排。液冷汇流排能承载超过5000安培电流,相当于20台电动汽车全速加速时的电流。总计130万个元件构成了第三代MGX机架设计。
与上一代Grace Blackwell相比,Vera Rubin在处理Agent任务时的吞吐量提升了10倍。黄仁勋透露,为Vera Rubin创建的供应链规模是Grace Blackwell的两倍。过去组装Grace Blackwell机架需要两小时,现在Vera Rubin仅需五分钟。这一效率提升得益于设计的改进。过去机架内存在大量线缆和软管,而现在采用PCB中板直接连接两侧,无需线缆、软管和风扇。整个系统采用液冷、模块化设计,并支持热插拔。
黄仁勋表示,在Hopper时代,最重要的工作是预训练;到Grace Blackwell时代,重点转变为推理。“许多人认为推理很简单,但推理就是金钱。”模型日益复杂,要在高响应速度、快速交互和高吞吐量下同时完成推理极具挑战。NVLink 72的价值正体现在此。黄仁勋指出,如今英伟达的TOKEN成本比竞争对手低一个数量级,这得益于其协同设计以及对推理计算模式的深刻理解。
目前已进入Agent时代,Agent不仅生成答案,还需要观察、推理、规划、使用工具,并管理大量的上下文、处理工作记忆和长期记忆,进而衍生出专家子Agent。Vera Rubin正是为这种工作负载而生。
Vera Rubin平台引入了英伟达Spectrum-X以太网光子技术。这是世界上首个基于共封装光学技术的交换机,拥有200Gb/s SerDes,现已投产。共封装光学技术与传统网络交换机不同,传统交换机使用可插拔收发器,需额外功率、散热和空间。共封装光学技术则将光学模块直接封装在交换机芯片上,并与台积电合作进行芯片级封装。这带来了三大优势:能效提升5倍,因为光学模块与芯片距离缩短,信号损耗更小;AI正常运行时间延长5倍,减少了可插拔部件的故障点;部署时间缩短三分之一,简化了设计,为计算释放了更多功率。
CoreWeave、Lambda和Oracle Cloud Infrastructure是首批采用共封装光学网络的合作伙伴。Lambda在其博客中展示了英伟达首批共封装光学样品开箱。黄仁勋表示,通过简化设计为计算释放更多功率,英伟达共封装光学网络为百万GPU AI工厂提供了基础架构。
Vera Rubin平台还集成了英伟达BlueField-4 DPU。BlueField-4拥有高达800Gb/s速度的软件定义网络和内置多租户隔离。借助英伟达BlueField-4 Advanced Secure Trusted Resource Architecture,客户可以简化网络操作,改善租户隔离,并在百万GPU AI集群中实现更大的控制。AI工厂越来越多地在Agent工作流中处理专有数据、受监管内容和关键任务模型。这要求在共享或云环境中,为自主Agent定制基础设施安全性,因为基础设施不能被隐式信任。
Vera Rubin平台设计了全栈英伟达机密计算,用于机架规模的可信执行环境。Vera Rubin NVL72将Vera CPU、Rubin GPU、英伟达NVLink网络和安全功能整合到统一平台中,在高速互连之间加密数据。这提供了硬件级认证,确保系统防篡改。在POD规模提供这种级别的保护,还需要可编程软件层,能够在整个系统中执行、编排和调整安全策略。英伟达DOCA软件平台在每个Vera Rubin平台机架和AI工厂层面提供安全性,通过直接在BlueField-4芯片中执行的能力保护数据、Agent、上下文内存和AI推理。
DOCA软件平台能够实现多租户网络隔离、零信任策略执行、运行时威胁检测以及高达800Gb/s速度的端到端加密,所有这些功能都不会占用主机CPU资源。因此,企业可以放心地扩展AI工厂。英伟达DSX平台为Vera Rubin AI工厂提供完整的设计和运营基础。DSX统一了参考设计、仿真、基础设施软件、设施和生态系统技术,旨在帮助构建和运营针对最低Token成本优化的节能AI工厂。
DSX是什么?黄仁勋解释道,全球正在建设AI工厂,这是一项大规模的基础设施建设。AI工厂的复杂性极高,芯片、机架、网络、电力、冷却、电网,每个层面都必须进行端到端协同设计,因为计算直接关联收入。英伟达DSX便是蓝图,是建设和运营AI工厂的参考设计,其核心目标是实现高效率和高盈利能力。DSX为Vera Rubin POD架构而构建,对齐堆栈的每一层,从芯片和系统到生命周期管理和多租户操作,旨在加速部署,提高规模化运营的可靠性和弹性。
戴尔科技、惠普、联想和Supermicro,以及华硕、富士康、技嘉、和硕、广达云科技、纬创和纬颖等公司正在采用英伟达DSX,以加速Vera Rubin AI工厂的建设。DSX包含三个部分。首先是DSX Sim。所有Omniverse Blueprint合作伙伴可以在第一台机架到位之前,就设计并验证一座英伟达Rubin AI工厂。他们可以规划布局、模拟电力和冷却、设计网络,并在数字孪生中验证每一次集成测试和每一次变更。其次是DSX OS。工厂通电后,DSX OS接管运营,提供监控和修复基础设施,将已安装系统转变为多租户、弹性、AI就绪的容量。最后是DSX Max-Q。
DSX Max-Q是什么?如今的AI工厂常常会过度配置电力40%,以应对峰值负载。DSX Max-Q则允许运营商在相同的电力预算下部署更多的GPU。它包含多项技术:温液冷却可在45摄氏度下运行,使用更少的水和能源,将更多能源留给计算;动态电力分配技术可以将机架电力导向需要工作的区域,回收闲置瓦特;机架内部的电力平滑机制可以削平峰值电流和电涌。在整个工厂中,AI Agent工作团队将通过DSX Max-Q持续协调,平衡冷却、电力和工作负载需求。DSX AI工厂还是弹性能源资产,可以与电网协同工作。DSX Flex能够读取实时电网信号,在电网需要缓解压力时动态调整工厂电力。
黄仁勋预估,到本十年末,将有100GW的AI工厂投入运行。由英伟达DSX运营的AI工厂将以最高效率生产最低成本的Token。Vera Rubin何时上市?生产出货将从今年秋季开始。
黄仁勋表示,过去英伟达是一家GPU公司。多年来,他们已经演变为一家系统公司。现在,我们看到的是英伟达最复杂的系统演进。最终客户和合作伙伴并非仅仅想购买一台计算机,他们更希望建设AI工厂。正因如此,英伟达正在再次转型,其技术已扩展到基础设施层面。
英伟达的合作伙伴涵盖发电、冷却、电网供应商以及工业基础设施公司。他们正努力构建完整的堆栈,正如他们为GPU、Grace Blackwell、NVLink 72所做的那样。如今,他们致力于构建完整的INFRASTRUCTURE系统,使客户能够建造AI基础设施。每个千兆瓦级的AI工厂投入都从200亿、300亿美元起步,很快将达到每千兆瓦800亿到1000亿美元。投入1000亿美元建设AI工厂,它必须一次性成功,并且必须立即奏效。
资本成本高昂,复杂性也极高。就像设计芯片时会先在计算机中模拟芯片,再模拟整个系统一样,现在也将AI工厂建在Omniverse中。这意味着可以在数字世界中建造这些系统,并在现实世界动工之前完成验证。RTX是GPU,DGX是系统,而现在DSX是基础设施。它包含了系统和软件,使英伟达能够与公司合作,将其转型为AI云。例如CoreWeave,其近期估值已达数百亿美元,并持续增长。
这些公司各自服务于区域客户,同时也服务全球客户。AI将无处不在,每家公司都将由AI驱动,每个地区都将建立自己的AI能力。它们需要完整的计算栈,包括硬件、软件、库,以及与第三方生态系统、第三方开发者连接的能力。协助客户建设和部署AI工厂至关重要,因为计算即收入,现在计算也意味着利润。没有收入、没有利润就意味着亏损。黄仁勋指出,这就是英伟达作为重要合作伙伴的原因。他们创造了完整的基础设施,将所有组件连接起来,并进行了验证,确保其正常运行。
首次Token生成时间更快,推理启动更迅速,从推理转向训练也更迅速。每瓦特产生的Token数量更多。这是因为所有组件都被整合起来,从头设计、模拟整个系统,并进行协同设计。可靠性也同样重要。大型数据中心拥有数百万条电缆和无数活动部件,要使这些计算机和谐工作极具挑战。英伟达长期运行超大规模系统的经验在此发挥关键作用。最后是产品寿命。
几年前Hopper时代的AI与现在已截然不同。六年前的Ampere时代还在讨论CNN,随后是Transformer,再后来提及专家混合,如今已是Agent系统。几乎每隔几个月,软件行业就会涌现新技术。如果架构缺乏灵活性,生态系统不够丰富,资产寿命就不会长久。由于全球软件开发者都在使用英伟达CUDA,因此英伟达CUDA生态的资产寿命会更长。从成本的另一面理解,如果资产寿命长,总拥有成本就低。这就是差异所在。
黄仁勋表示,买得越多,赚得越多。全球的工厂和员工都在全力以赴,因为全世界都渴望盈利。人们已经意识到,真正有用的AI已经到来,可盈利的AI也已实现,计算需求之高令人震惊,而需求本身就是一种限制。
黄仁勋今日还发布了开源大模型Nemotron 3 Ultra。Nemotron是英伟达为全球构建的专用开源模型,专为Agent工作负载而设计。与其他开源模型不同,Nemotron不仅提供模型本身,还提供训练模型所用的数据。Nemotron针对长时间推理、长时间运行的工具任务、工具使用和任务解决进行了训练,是世界上最大的长时程推理模型之一。模型、训练脚本和数据全部开源。黄仁勋表示,这是开源模型的最佳形态,允许用户获取、继续添加数据,使其变得更好,并成为自己的模型。
Nemotron 3 Ultra主要具备三大优势。首先,速度快近五倍。它是世界上首批基于混合架构的模型之一,结合了状态空间模型(SSM)与专家混合(MoE),这种架构速度极快。黄仁勋指出,更快的速度意味着在同等成本下,能进行更长时间的思考。其次,运行成本降低约30%。再次,它完全开源,包括模型、训练脚本和数据。
那么,Nemotron 3 Ultra的具体用途是什么?黄仁勋举了一个案例。他表示,英伟达如今制造芯片的复杂度极高,工程师需要逐行检查、反复进行验证,这既耗时又昂贵。每颗AI芯片内含海量晶体管,每条线路、每个逻辑门都必须严丝合缝,哪怕一个微小的错误,都可能导致整颗芯片延期数月。因此,英伟达与Cadence共同组建了一个“芯片设计AI助手团队”。
这个团队由一组具备执行能力的Agent构成。它能够阅读芯片设计规格,编写或修改RTL代码,自动生成测试用例,调用Cadence的仿真工具Xcelium运行模拟,并利用Jasper进行形式化验证。一旦发现Bug,它还能定位问题、修改代码,并重新运行验证。在这个过程中,大致分工如下。