过去十年,我们见证了数据存储从企业级阵列到个人NAS设备的演变,这背后是硬盘成本降低、硬件功耗优化和用户对隐私的关注,促使数据所有权逐步回归家庭。如今,同样的变革正降临到AI算力领域。
AI算力正处于一个与十年前存储下沉相似的关键时期。2024年,群晖率先推出带专用NPU的NAS产品,并非偶然现象。包括威联通、极空间、绿联在内的主要NAS制造商,都已将“本地AI”功能纳入2025年的产品规划。曾仅作为数据存储的NAS,正转型为兼具思考能力的“家庭算力枢纽”。
究竟为何需要这样的“家庭大脑”?上世纪六十年代,IBM 360大型机占据整个房间,计算是少数人特权;三十年前,个人电脑的普及实现了通用算力的全民化。而今天,随着AI Agent需7×24小时在线、大模型推理对显存巨大需求,以及家庭隐私数据不愿上云,AI算力也正从机房走向客厅,家庭成为了AI应用的终极边缘节点。
首先是严峻的隐私挑战。家庭场景蕴含着用户极其私密的数据和个性化习惯,如照片、健康记录、消费偏好和作息规律,这些数据属性决定了其不可外泄性。现有多数设备要么依赖云端难以处理复杂本地任务,要么侧重通用计算却缺乏常态化的主动智能。
其次是经济考量。目前主流云端AI服务多采用订阅制。若以多成员、多设备、多Agent的家庭场景计算,每月数百元的“AI税”累积起来,两年内即可抵消一台本地算力设备的购置费用。家庭AI中枢一旦投入,即可拥有终身算力使用权,全天候运行本地大模型。
真正将家庭算力枢纽从“锦上添花”转变为“刚需”的,是即将到来的AI Agent时代。AI Agent并非简单的问答式搜索引擎,而是持续在线、主动感知并自主执行的数字生命体。诸多家庭应用场景对响应速度和可靠性有着严苛要求,云端方案即使只有百毫秒延迟,在Agent语境下也显迟钝;网络中断更是致命。唯有本地算力,方能提供真正的实时响应和断网自治。
现有的家庭网络结构本质上是“各设备独立思考”:手机内置NPU,电脑配备GPU,智能音箱有专属语音芯片。这如同早期每个房间单独安装空调,各自为政,效率低下。家庭算力枢纽的目标,则是构建AI时代的“中央空调”:一个强大统一的计算核心,通过家庭局域网向所有终端设备按需提供“智能”。技术上克服障碍后,剩下的挑战主要集中在成本、产品形态和生态建设。
家庭算力枢纽的形态呈现了多元化发展。市场上已涌现出多种路线,体现了对“家庭AI”的不同理解。
一类是日益趋近服务器的NAS。NAS厂商是首批洞察趋势者。自2025年起,绿联、极空间、威联通几乎所有新品均打上“AI”标签。AI NAS的优势在于用户已有数据存储需求,算力成为附加价值,用户迁移成本低。然而,其瓶颈在于传统NAS处理器的AI算力有限(如Intel N305/N355),通常仅能流畅运行7B以下的小模型,对于30B以上的实用级模型则力不从心。
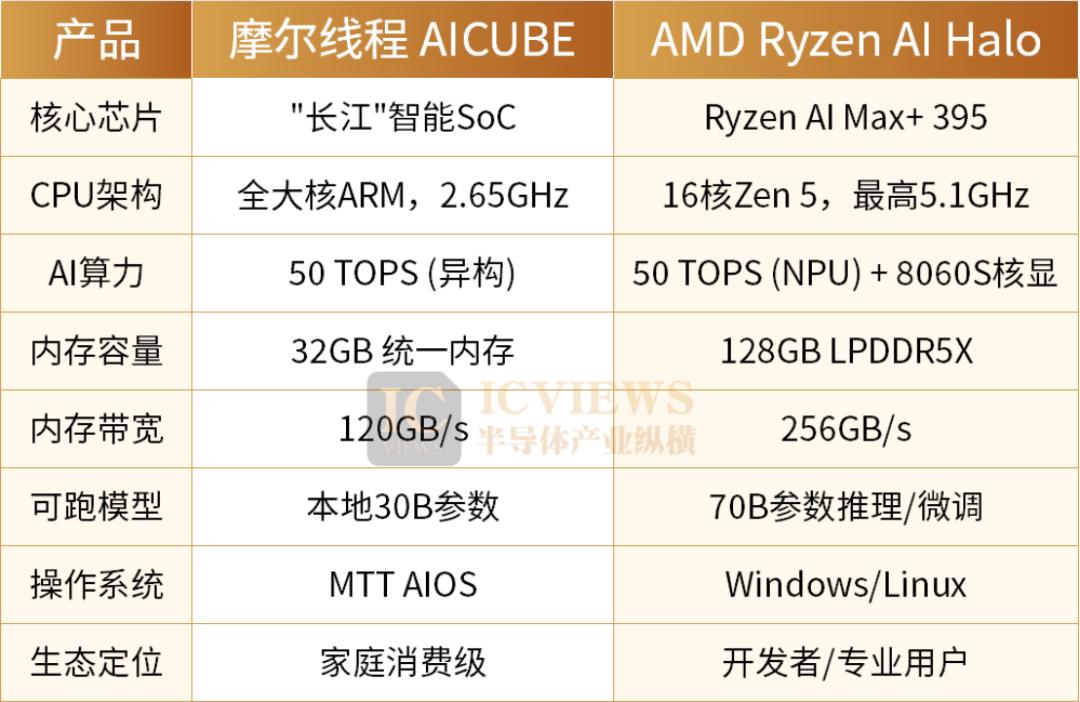
另一形态是迷你主机/AI BOX。与NAS的“存储优先”理念不同,迷你主机/AI BOX更侧重算力。2026年初,苹果M4 Mac mini全球断货事件堪称算力下沉家庭的标志性时刻。开发者们发现,这款3000元级别的迷你主机凭借38 TOPS的NPU算力、16-32GB统一内存架构及超低待机功耗,成为运行本地AI Agent的理想选择。此外,AMD的锐龙AI Max+ 395(代号“Strix Halo”)也向家庭算力枢纽市场投下重磅炸弹,其配备16核Zen5 CPU、40单元RDNA3.5 GPU、50 TOPS NPU,并支持高达128GB统一内存(最高96GB可专供GPU显存)。这意味着一台小巧设备能本地运行Llama 3.1 70B-Q8、GPT-OSS-120B等千亿参数模型。迷你主机的优势在于纯粹的算力密度和架构先进性,但劣势是存储扩展性通常不及NAS,且需用户自行搭建软件生态。
还有一种可能性是AI原生中枢。2026年5月18日,摩尔线程发布了MTT AICUBE。它不将自己定义为NAS或PC,而是“家庭AI中枢”。AICUBE搭载自研的“长江”智能SoC,集成了全大核CPU、全功能GPU和双核NPU,提供50TOPS的异构AI算力及32GB高速统一内存(带宽120GB/s)。AICUBE的雄心在于构建生态闭环:从芯片(长江SoC)到系统(MTT AIOS),再到智能体(小麦)和存储(全闪AI NAS)全部自主研发。这种垂直整合使其能提供传统PC厂商无法比拟的用户体验,例如其“二维拓扑记忆系统”,让AI真正拥有长短期记忆融合能力,越使用越能理解家庭成员偏好。
这三条路线的根本分歧在于:AI NAS认为“数据是核心,算力是附属”;迷你主机则坚信“算力是核心,存储可外接”;而AICUBE则提出“Agent才是核心,算力与存储仅是Agent的延伸”。
统一内存架构(UMA)或将是破解当前瓶颈的关键。家庭算力枢纽能否普及,瓶颈从未在于CPU主频,而在于内存墙。在传统PC架构中,CPU拥有DDR内存,GPU配备GDDR显存,两者通过PCIe总线通信。大模型推理时,数据需在内存和显存间频繁传输,这不仅消耗带宽,还增加功耗和时间。更关键的是,对于参数量动辄数十亿的大模型,显存容量直接决定了其可运行模型的规模。消费级独立显卡通常仅有8-16GB显存,运行Stable Diffusion 3.5 Large等模型时可能捉襟见肘。
UMA正是打破这一壁垒的关键技术。它使CPU、GPU、NPU共享一个物理内存池,通过片上高速互连动态分配资源。这带来多项优势:首先是零拷贝通信,CPU预处理的数据可供GPU直接读取,无需PCIe传输;其次是显存弹性扩容,系统内存可动态分配给GPU,从而加载更大模型;最后是带宽效率大幅提升。
目前,三大芯片厂商均积极推动UMA在消费级市场的应用。AMD的Strix Halo将此逻辑引入消费级产品,其128GB LPDDR5X-8000统一内存,通过GTT(图形转换表)使GPU直接访问系统内存,其中约96GB可分配给AI推理,使其成为首款能在单机上运行70B全精度模型的消费级处理器。NVIDIA DGX Spark搭载的GB10芯片也采用128GB统一内存,带宽高达273GB/s,可分配约100GB作为显存,但目前主要面向专业AI开发者。苹果M4 Max的统一内存带宽超过500GB/s,系三者之最,但其封闭生态意味着用户无法自由安装模型、扩展硬件或选择操作系统,这对需要长期迭代和灵活部署的家庭算力枢纽而言,封闭性是致命缺陷。
家庭算力枢纽的终极价值,不在于其能运行多大的模型,而在于它能解决当前AI生态中的“失忆症”顽疾。如今的AI设备宛如一座座“智能孤岛”。手机上的助手无法了解PC内的文档,音箱也无从知晓电视的观看历史,每个设备都需重新学习用户的偏好。家庭算力枢纽的颠覆性意义在于,它能成为整个家庭的统一记忆层,所有设备通过本地网络连接同一算力中枢,实现真正的语义级记忆共享,而非云端账户简单的“同步文件夹”。摩尔线程的“小麦”智能体已展示这种可能性:其二维拓扑记忆系统深度融合短长时记忆,能精准关联人与事、过去与现在。
要构建这种真正的“家庭记忆”,需要一套三层架构体系:
第一层是统一向量数据库。家庭所有非结构化数据,包括照片、文档、聊天记录和健康数据,都被转化为向量嵌入,集中存储在枢纽中。任何设备的AI请求,都首先查询这个“家庭知识库”。
第二层是跨设备Agent协作。手机负责采集(如拍照、录音),PC负责生产(如写作、编程),电视负责展示(如相册、视频),音箱负责交互(如语音入口)。这些设备并非各自运行AI,而是将感知任务本地处理后,将推理任务交由枢纽完成,再将结果返回至各自终端呈现。
第三层是上下文继承。通过家庭局域网的身份识别(例如谁在哪个房间、使用何种设备),枢纽维护一个持续的对话状态。用户在客厅开始的问题,可在卧室继续,因为“记忆”不再依附于特定设备,而是存储在枢纽之中。
这种模式还带来一个副产品:本地Agent的算力供给。目前的AI Agent要么运行在云端,要么运行在本地PC。家庭算力枢纽提供了一个中间状态:足够强大的本地算力(支持70B模型+向量数据库),极低的延迟(局域网毫秒级),以及高度隐私(数据不出家门)。算力枢纽使得“Agent私有化”从极客实验变为家庭标配。
未来的家庭数字基础设施将由三大支柱构成:网络底座(路由器已普及)、存储底座(NAS或本地服务器正在普及),以及算力底座(家庭AI枢纽即将普及)。三者融合,便构成了“家庭边缘节点”的终极形态。它将了解全家人的喜好,管理所有数据,驱动所有智能设备,且无需将隐私数据上传至云端。
从大型机到PC,从交换机到路由器,从企业存储到NAS——历史反复印证,算力的最终归宿并非遥远的数据中心,而是用户触手可及之处。算力正正式下沉至家庭,这不仅是技术的演进,更是数字主权的回归。